ANYACCOMP: GENERALIZABLE ACCOMPANIMENT GENERATION VIA QUANTIZED MELODIC BOTTLENECK
Junan Zhang☆ Yunjia Zhang☆ Xueyao Zhang Zhizheng Wu
The Chinese University of Hong Kong, Shenzhen
Abstract
State-of-the-art Singing Accompaniment Generation (SAG) models rely on source-separated vocals, causing them to overfit to separation artifacts. This creates a critical train-test mismatch, leading to failure on clean, real-world vocal inputs. We introduce AnyAccomp, a framework that resolves this by decoupling accompaniment generation from source-dependent artifacts. AnyAccomp first employs a quantized melodic bottleneck, using a chromagram and a VQ-VAE to extract a discrete, timbre-invariant representation of the core melody. A subsequent flow-matching model then generates the accompaniment conditioned on these robust codes. Experiments show AnyAccomp achieves competitive performance on separated-vocal benchmarks while significantly outperforming baselines on generalization test sets of clean studio vocals and, notably, solo instrumental tracks. This demonstrates a qualitative leap in generalization, enabling robust accompaniment for instruments—a task where existing models completely fail—and paving the way for more versatile music co-creation tools.
Framework Overview
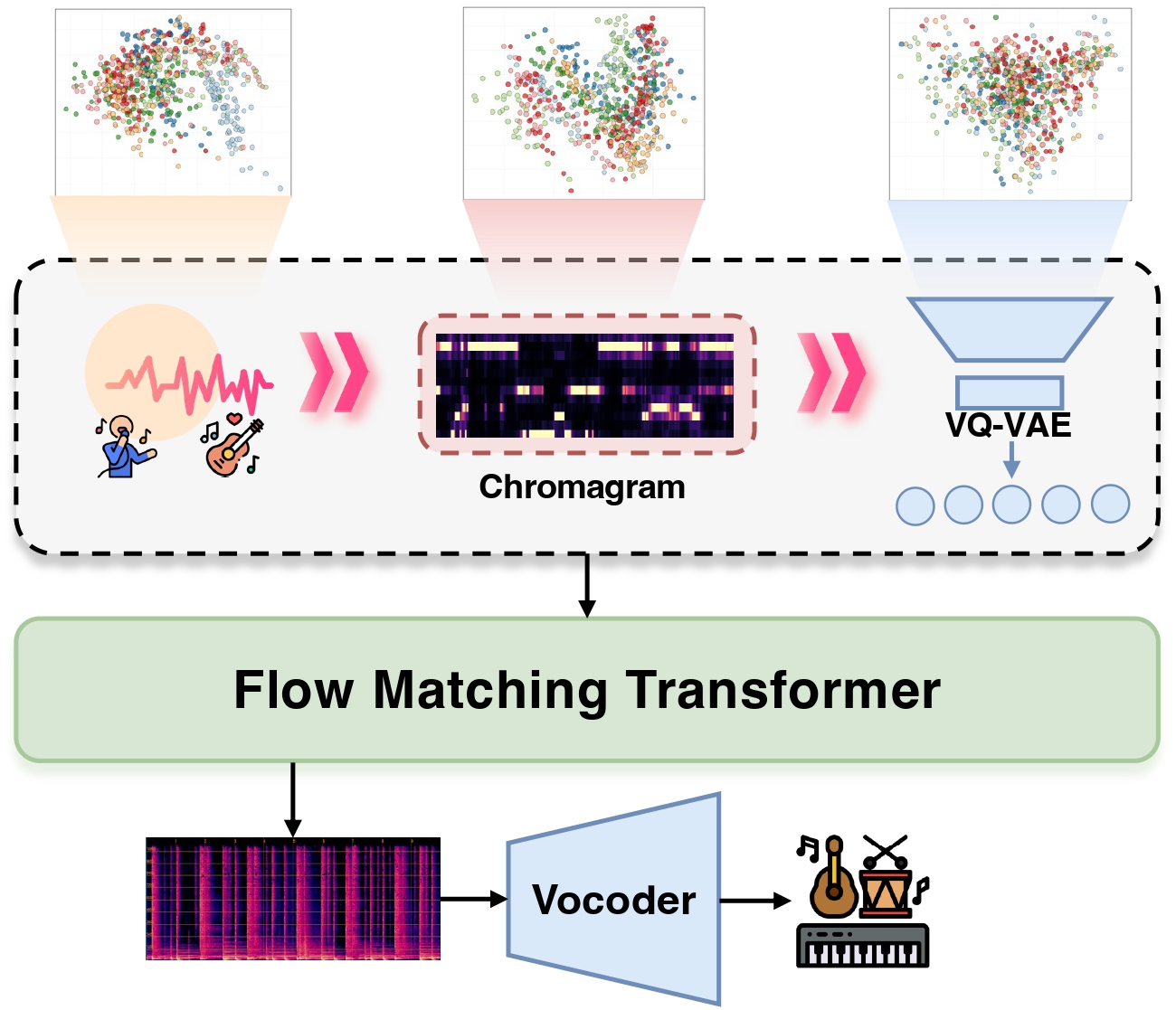
An overview of ANYACCOMP. The process involves two main stages:
(1) The input audio is processed through a quantized melodic bottleneck, where a VQ-VAE encodes its chromagram into a sequence of discrete tokens.
(2) A Flow Matching Transformer generates a mel-spectrogram conditioned on these discrete tokens, which is subsequently synthesized into the final accompaniment audio by a vocoder.
Empirical Experiments
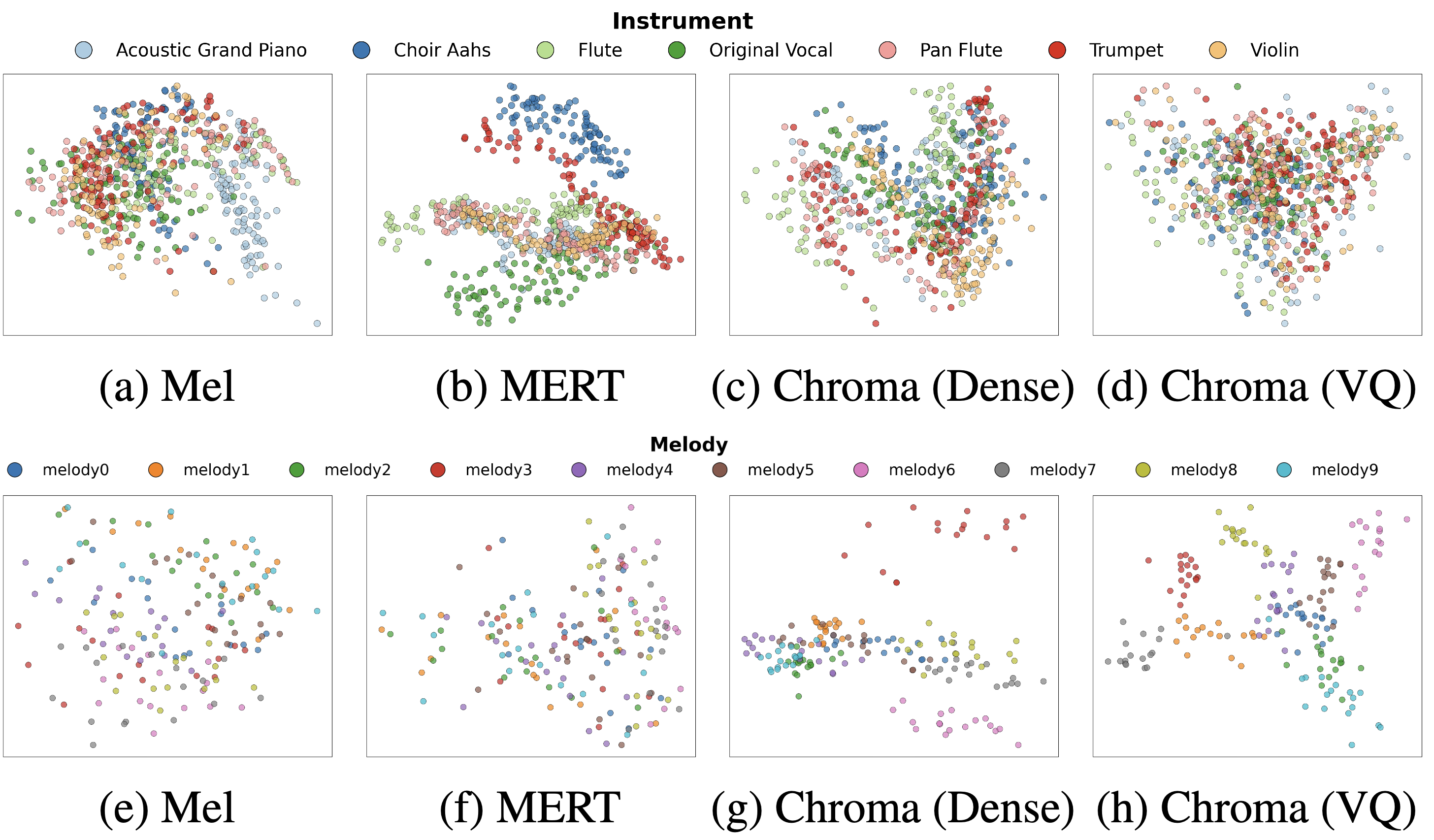
Fig. 2: Visualization of different representations. The top row evaluates timbre invariance (better = more intermingled). The bottom row assesses melodic clusterability (better = tighter clusters).
In this paper, we view the SAG task as a conditional generation problem, focusing on identifying a suitable condition representation. Such a representation should satisfy two key properties: timbre invariance and melodic clusterability.
Timbre invariance. A robust representation must be agnostic to the source timbre, a property crucial for generalization. As visualized in the top row of the figure, the traditional mel spectrogram fails this test, exhibiting strong clustering by instrument type. The dense chromagram significantly mitigates this bias. However, it is our final vector-quantized chromagram representation that achieves the ideal result: a feature space where points from all instruments are thoroughly intermingled, demonstrating a successful decoupling of melodic content from source timbre.
Melodic clusterability. An effective representation must map identical melodies to compact regions in the feature space, irrespective of the instrument. The bottom row of the figure illustrates a clear progression. While the mel spectrogram fails to form coherent clusters, the dense chromagram shows a marked improvement. Our final vector-quantized chromagram representation further refines this by producing exceptionally tight and well-separated clusters, creating a highly robust condition for the generative model.